x <- .Last.valuehelps you, without reading it again..., it is the same for the result of every other function
Saturday, June 25, 2011
R - get back the last result (if it was forgotten to assign it)
R stores the result of the LAST operation in .Last.value;
So, for example, if you read a file into R and forgot to assign it,
R - working with unique() and duplicated()
duplicated() vs. unique()
- first we create a vector we can work with:
x <- sample(LETTERS[1:10], 20, replace=T) x
[1] "J" "C" "J" "C" "F" "J" "E" "J" "H" "A" "C" "G" "I" "A" "F" "H" "J" "C" "C" [20] "D"
- unique() gives us a vector containing every new element of x but ignores repeated elements
unique(x)
[1] "J" "C" "F" "E" "H" "A" "G" "I" "D"
- duplicated() gives a logical vector
duplicated(x)
[1] FALSE FALSE TRUE TRUE FALSE TRUE FALSE TRUE FALSE FALSE TRUE FALSE [13] FALSE TRUE TRUE TRUE TRUE TRUE TRUE FALSE
- so if we want to get the same result like the one from unique we have to index x in the following way:
x[duplicated(x)==F]
[1] "J" "C" "F" "E" "H" "A" "G" "I" "D"
- if we want to get just repeated occurences (i.e. a vector without the first occurence) we use the following line
x[duplicated(x)==T]
[1] "J" "C" "J" "J" "C" "A" "F" "H" "J" "C" "C"
- we can use these commands the same way on dataframes, so let our x code persons, and we add a numeric value which could be a measurement and the order of the vector describes the order in which the measurements are taken
y <- rnorm(20, mean=10) df <- data.frame(person=x, meas=y) df
person meas 1 J 11.180452 2 C 10.235697 3 J 10.908622 4 C 10.677399 5 F 8.564007 6 J 10.070557 7 E 10.144191 8 J 10.872314 9 H 11.635032 10 A 10.448090 11 C 10.642052 12 G 8.689660 13 I 10.007930 14 A 8.321125 15 F 10.610739 16 H 9.060412 17 J 10.678726 18 C 8.513766 19 C 8.851564 20 D 12.793154
- we extract the first measurement of each person with (the comma behind the F is important - it says we want the whole line)
df[duplicated(df$person)==F,]
person meas 1 J 11.180452 2 C 10.235697 5 F 8.564007 7 E 10.144191 9 H 11.635032 10 A 10.448090 12 G 8.689660 13 I 10.007930 20 D 12.793154
- and with the following command we can extract the follow up measurements
df[duplicated(df$person)==T,]
person meas 3 J 10.908622 4 C 10.677399 6 J 10.070557 8 J 10.872314 11 C 10.642052 14 A 8.321125 15 F 10.610739 16 H 9.060412 17 J 10.678726 18 C 8.513766 19 C 8.851564
- we also can use duplicate in a recursive way; the result of the following function is a list containing vectors whereupon the first contains the first occurence, the second the second, etc.; you can change it easily: so it can give back logical vectors which can use to index a dataframe, or for working on a dataframe itself (which both would be more useful)
sep.meas <- function(dupl){
res <- list()
while(length(dupl)>0){
res[[length(res)+1] ] <- dupl[duplicated(dupl)==F]
dupl <- dupl[duplicated(dupl)==T]
}
res
}
- if we use it on x we get the following result
sep.meas(x)
[[1]] [1] "J" "C" "F" "E" "H" "A" "G" "I" "D" [[2]] [1] "J" "C" "A" "F" "H" [[3]] [1] "J" "C" [[4]] [1] "J" "C" [[5]] [1] "J" "C"
R - sorting vectors: sort() vs. order()
sort() and order()
- both operates on vectors and has the same aim, but the results are very different
x <- sample(LETTERS[1:10], 100, replace=T) # create a vector to sort by sampling from the first 10 Letters of the alphabet 100 times x
[1] "H" "D" "I" "E" "F" "B" "E" "G" "D" "A" "H" "I" "E" "A" "E" "A" "I" "J" [19] "I" "A" "B" "F" "A" "I" "F" "B" "A" "H" "J" "A" "E" "A" "C" "A" "A" "C" [37] "F" "C" "D" "G" "I" "I" "B" "J" "J" "D" "I" "J" "G" "J" "A" "B" "B" "C" [55] "A" "B" "D" "E" "D" "D" "E" "J" "A" "J" "G" "D" "A" "B" "D" "I" "F" "H" [73] "D" "J" "D" "E" "E" "A" "A" "J" "B" "E" "C" "I" "C" "F" "F" "E" "E" "J" [91] "H" "H" "F" "I" "A" "I" "H" "I" "I" "I"
- the result of sort() is a vector consisting of elements of the original (unsorted) vector
sort(x)
[1] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "B" [19] "B" "B" "B" "B" "B" "B" "B" "B" "C" "C" "C" "C" "C" "C" "D" "D" "D" "D" [37] "D" "D" "D" "D" "D" "D" "D" "E" "E" "E" "E" "E" "E" "E" "E" "E" "E" "E" [55] "E" "F" "F" "F" "F" "F" "F" "F" "F" "G" "G" "G" "G" "H" "H" "H" "H" "H" [73] "H" "H" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "J" [91] "J" "J" "J" "J" "J" "J" "J" "J" "J" "J"
- if we do the same with order the result is completely different - we get a vector with the ordered indices of the original (unsorted) vector
order(x)
[1] 10 14 16 20 23 27 30 32 34 35 51 55 63 67 78 79 95 6 [19] 21 26 43 52 53 56 68 81 33 36 38 54 83 85 2 9 39 46 [37] 57 59 60 66 69 73 75 4 7 13 15 31 58 61 76 77 82 88 [55] 89 5 22 25 37 71 86 87 93 8 40 49 65 1 11 28 72 91 [73] 92 97 3 12 17 19 24 41 42 47 70 84 94 96 98 99 100 18 [91] 29 44 45 48 50 62 64 74 80 90
- if you want to get the ordered vector (like with sort()) you have to index the original vector with the vector of the indices
x[order(x)]
[1] "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "A" "B" [19] "B" "B" "B" "B" "B" "B" "B" "B" "C" "C" "C" "C" "C" "C" "D" "D" "D" "D" [37] "D" "D" "D" "D" "D" "D" "D" "E" "E" "E" "E" "E" "E" "E" "E" "E" "E" "E" [55] "E" "F" "F" "F" "F" "F" "F" "F" "F" "G" "G" "G" "G" "H" "H" "H" "H" "H" [73] "H" "H" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "I" "J" [91] "J" "J" "J" "J" "J" "J" "J" "J" "J" "J"
Friday, June 24, 2011
Org-Mode: use ASCII - graphics
install ditaa (command line utility written in Java);
Download and a how to here:
Homepage;
there is also an ubuntu package (named also ditaa)
Thursday, June 23, 2011
test latex embedding...
When \(a \ne 0\), there are two solutions to \(ax^2 + bx + c = 0\) and they are
$$x = {-b \pm \sqrt{b^2-4ac} \over 2a}.$$
- a ratio is the comparison of two numbers that can be expressed as quotient $$a:b = \frac{a}{b}$$
Ratios, rates, proportion and odds
- ratios
- a ratio is the comparison of two numbers that can be expressed as quotient $$a:b \rightarrow \frac{a}{b}$$
- rate
- a rate is a type of ratio, expressed as a quotient, comparing the change in one value (numerator) per change in another value (denominator): $$\Delta a:\Delta b \rightarrow \frac{\Delta a}{\Delta b} $$
- example: death rate, calculate as the number of deaths divided by the person time at risk
- proportion
- a proportion is a type of ratio, expressed as a quotient, comparing a part (numerator) to the whole (denominator): $$ a:(a+b) \rightarrow \frac{a}{a+b}$$
- odds
- is a type of ratio, expressed as quotient, comparing a part (numerator) to the remainder (denominator): $$c:d \rightarrow \frac{c}{d}$$
Org-Mode: enable R support
Add the following code to the Emacs configuration file (.emacs in your home directory). If this file does not exist yet, create it:
;; active Babel languages (org-babel-do-load-languages 'org-babel-load-languages '((R . t) (emacs-lisp . nil) ))And restart emacs!
Monday, June 20, 2011
Wednesday, June 15, 2011
R Windows binaries rjava
now again available on CRAN
Sunday, June 12, 2011
R - ggplot2: qplot
ggplot
Table of Contents
1 ggplot intro
1.1 first examples ggplot
The next view lines are the first examples in the book ggplot from the author of the package H. Wickham - just a overview what is possible with qplot(); the diamond data set is a part of the ggplot2 package.
- first load the package
- load the data set
- create a small data set from diamonds using sample() (1000 rows)
- have a look on the data (head())
library(ggplot2) data(diamonds) dsmall <- diamonds[sample(nrow(diamonds),1000),] head(diamonds)
carat cut color clarity depth table price x y z 1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63 5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
- and str()
str(diamonds)
'data.frame': 53940 obs. of 10 variables: $ carat : num 0.23 0.21 0.23 0.29 0.31 0.24 0.24 0.26 0.22 0.23 ... $ cut : Factor w/ 5 levels "Fair","Good",..: 5 4 2 4 2 3 3 3 1 3 ... $ color : Factor w/ 7 levels "D","E","F","G",..: 2 2 2 6 7 7 6 5 2 5 ... $ clarity: Factor w/ 8 levels "I1","SI2","SI1",..: 2 3 5 4 2 6 7 3 4 5 ... $ depth : num 61.5 59.8 56.9 62.4 63.3 62.8 62.3 61.9 65.1 59.4 ... $ table : num 55 61 65 58 58 57 57 55 61 61 ... $ price : int 326 326 327 334 335 336 336 337 337 338 ... $ x : num 3.95 3.89 4.05 4.2 4.34 3.94 3.95 4.07 3.87 4 ... $ y : num 3.98 3.84 4.07 4.23 4.35 3.96 3.98 4.11 3.78 4.05 ... $ z : num 2.43 2.31 2.31 2.63 2.75 2.48 2.47 2.53 2.49 2.39 ...
Now we can start:
1.1.1 Simple Barcharts and Histograms
barchart of the variable cut which is a factor with five levels
qplot(cut, data=diamonds, geom="bar")

trying the same with a numeric (continuous) variable e.g. depth; Histogram:
qplot(depth, data=diamonds, geom="histogram")

If we look at this picture we notice ggplot has set the range of the x-axis apparently to wide. Type
range(diamonds$depth)
[1] 43 79
which give the min and the max of the depths
if you still want to change the visible part of the x-axis, you can do it with the xlim argument:
qplot(depth, xlim=c(55,70), data=diamonds, geom="histogram")
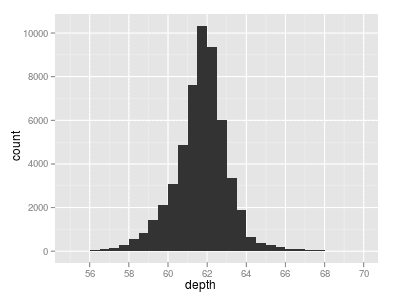
Besides the image R gives you the following line as result:
stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.
so if you want to change the width of the bins add the binwidth argument
Now we have a look on the distribution of carat of the diamonds and change this argument:
qplot(carat, data=diamonds, geom="histogram", binwidth=1)

qplot(carat, data=diamonds, geom="histogram", binwidth=0.1)

qplot(carat, data=diamonds, geom="histogram", binwidth=0.01)

Every step we have a gain of information, the more bins we have the more information we get from the image.
1.1.2 Density Plots
For continuous variables you can use density instead of histogram.
qplot(carat, data=diamonds, geom="density")

If we want to compare different groups defined by a factor, we simply add the colour argument. Here we use the variable diamonds$color.
qplot(carat, data=diamonds, geom="density", colour=color)

Too many curves on one plot? No problem: we add a facets argument, which splits the one above into as many as levels of color
qplot(carat, data=diamonds, geom="density", facets=color~., colour=color)

And if we want to fill the curve (in the same color):
qplot(carat, data=diamonds, geom="density", facets=color~., colour=color, fill=color)

If you want to put two plots side by side on one image, use grid.arrange(). Install the package (if it is not installed yet) via install.packages("gridExtra").
First we load the library:library(gridExtra)
Now we can look at the densities depending on the color in on hand and clarity on the other:
p1 <- qplot(carat, data=diamonds, geom="density", facets=clarity~., fill=clarity) p2 <- qplot(carat, data=diamonds, geom="density", facets=color~., fill=color) grid.arrange(p1,p2, ncol=2)

Scatter Plots
Giving two arguments x and y to qplot() we will get back a scatter plot, through which we can investigate the relationship of them:
qplot(carat, price, data=diamonds)

qplot() accepts functions of variables as arguments:
qplot(log(carat), log(price), data=diamonds)

By using the colour argument, you can use a factor variable to color the points. In this example I use the column color of the diamonds data frame to define the different groups. The further argument alpha changes the transparency, it is numeric in the range [0,1] where 0 means completely transparent and 1 completely opaque. I() is a R function and stands for as is.
qplot(log(carat), log(price), data=diamonds, colour=color, alpha=I(1/7))

Instead of colour you can use the shape argument, it is more helpful especially when you are forced to create bw graphics. Unfortunately shape can only deal with with a maximum of 6 levels. So I chose the column cut. And - of course - it is more appropriate to use a smaller dataset. Additionally we use the size argument to change the size of the points according to the volume of the diamonds (the product x*y*z).
qplot(log(carat), log(price), data=dsmall, shape=cut, size=x*y*z)

Via geom argument (which is useful in lots of other ways) we can add a smoother (because we want to keep the points we also add point). You can turn off the drawing of the confidence interval by the argument se=FALSE.
qplot(log(carat), log(price), data=dsmall, geom=c("point","smooth"))

With method you can also change the smoother: loess, gam, lm etc pp.
qplot(log(carat), log(price), data=dsmall, geom=c("point","smooth"), method="lm")

Date: 2011-06-12 13:04:25 CEST
HTML generated by org-mode 7.4 in emacs 23
Thursday, June 9, 2011
GoogleTechTalks David Mease
Wednesday, June 8, 2011
R - how-to-install-r-jgr-and-deducer-in-ubuntu
You need this:
http://www.seancsb.net/statistical/installing-jgr-and-deducer And a lot of time....
OR if you haven't got a lot of time use this script. Run the script as root, just sudo does NOT work properly.
http://www.seancsb.net/statistical/installing-jgr-and-deducer And a lot of time....
OR if you haven't got a lot of time use this script. Run the script as root, just sudo does NOT work properly.
R - add cran as ubuntu repository and update R
For 11.04
- sudo add-apt-repository "deb http://cran.rakanu.com/bin/linux/ubuntu natty/"
- gpg --keyserver keyserver.ubuntu.com --recv-key E084DAB9
- gpg -a --export E084DAB9 | sudo apt-key add -
- sudo apt-get update
- sudo apt-get upgrade
R - converting integers or strings into date format
- as.Date(x,format="")
- dates are given in a lot of different formats, e.g.
- "2011-03-14"
- "2011-Mar-14"
- "11-March-14"
- if you want to convert them you have to tell R which format your dates have, here some examples:
- here are the codes:
Code Value %d Day of the month (decimal number) %m Month (decimal number) %b Month (abbreviated) %B Month (full name) %y Year (2 digits) %Y Year (4 digits) - if the date is given as integer you have to specify the origin - R counts in days. e.g. in SPSS a date is stored in seconds, the origin is 1582-10-14. So you have divide by 86400 (=24*60*60); for example if 1000000 is given the command is:
| > as.Date("2011-03-14",format="%Y-%m-%d") |
| [1] "2011-03-14" |
| > as.Date("2011/03/14", format="%Y/%m/%d") |
| [1] "2011-03-14" |
| > as.Date("14.3.2011", format="%d.%m.%Y") |
| [1] "2011-03-14" |
| > as.Date("2011-Sep-14", format="%Y-%b-%d") |
| [1] "2011-09-14" |
| > as.Date("2011-september-14", format="%Y-%B-%d") |
| [1] "2011-09-14" |
| > as.Date("14. November 1999", format="%d. %B %Y") |
| [1] "1999-11-14" |
| > as.Date(1000000/86400, origin="1582-10-14") |
| [1] "1582-10-25" the origin in Excel: 1900-01-01; SAS: 1960-01-01; R: 1970-01-01 |
R - import excel file
- the command read.xls("Path/to/data/data.xls") is part of the gdata package, so you have to install and load it
- str() shows the structure of the read data
library(ggplot2)
> x<-read.xls("c:\\R\\20110511daten.xls") # on Win
> x<-read.xls("~/R/20110511daten.xls") # on Unix
> str(x)
'data.frame': 7554 obs. of 20 variables:
$ sex : int 1 1 1 1 1 0 0 0 0 0 ...
$ date : Factor w/ 4312 levels "1966-Mar-01",..: 609 655 704 175 1920 2033 217 1899 977 ...
$ month : int 3 12 7 12 11 6 11 11 6 1 ...
$ year : int 2011 2008 2007 2007 2010 2008 2010 2007 2010 2010 ...
$ age : num 17.5 15.9 14 17.9 12.6 ...
everything is fine except the second variable: date is read as a factor not as date time; it has to be converted into a date. - above you can see date is stored as "year-month-day"
- so all we have to do is the following:
library(ggplot2)> x$date<-as.Date(x$date, format="%Y-%b-%d") > str(x) 'data.frame': 7554 obs. of 21 variables: $ sex : int 1 1 1 1 1 0 0 0 0 0 ... $ date :Class 'Date' num [1:7554] 8629 8407 8572 7315 10342 ... $ month : int 3 12 7 12 11 6 11 11 6 1 ... $ year : int 2011 2008 2007 2007 2010 2008 2010 2007 2010 2010 ...
> summary(x$date)
| Min. | 1st Qu. | Median | Mean | 3rd Qu. | Max. |
| "1975-11-06" | "1995-08-13" | "1999-02-09" | "1998-12-31" | "2002-09-10" | "2008-02-17" |
Tuesday, June 7, 2011
R - plotting means and Confidence Intervals
- you need the package gplots, which requires the packages bitops and caTools, so install them using the command
> install.packages(c("bitops","caTools","gplots"))
- load gplots
> library(gplots)
- plotmeans(formula)
Example:
# Create a vector which will define the groups (1,2,...,10)
> x <- rep(1:10,10) # Create a vector consisting of 100 random values from a normal distribution > y <- rnorm(100) # Plotting > plotmeans(y~x)

- If x and y are part of a dataframe my.df you have to specify the dataframe:
plotmeans(y~x, data=my.df) - The default confidence interval is 95%; you can change it with the p argument:
plotmeans(y~x, p=0.9) plots the mean with 90%-confidence intervals - changing the argument ci.label to TRUE adds the values the CIs, n.label works on the n's of the groups (above the x-axis)
- you can also replace the circle for the mean by the value of the mean (via mean.labels=T)
- the arguments ccol, barcol, col change the color of the line connecting the means, the bars, the text
Example:
# 50%-CI, labled CIs
> plotmeans(y~x, p=.5, main="50%", mean.labels=F, ci.label=T, n.label=F, ccol="red", barcol="green", col="darkgreen")

Sunday, June 5, 2011
Properties in Org-Mode
- insert a property: C-c C-x p
- TAB after an initial colon in a line completes a property key
R - pairs plot
- produces a scatterplot matrix
- with the panel argument you can include smoothers
- the unclass command changes the factor iris$Species into a vector of integers - so you can use it to define the colors of the points
example:
> data(iris)
> pairs(iris[1:4], main="Edgar Andersons Iris Data", panel=panel.smooth, pch=21, bg=c("red","green","blue")[unclass(iris$Species)],lwd=2,lty=2)
plot:

R - conditional plot
- coplot is a graphical method by which you can show how a response depends on a predictor given other predictors
- cut(var, n) cuts a continuous variable into n intervals, you can also specify your own breakpoints (breaks=c()); the result of cut is a factor
example code:
> attach(iris)
> coplot(Sepal.Length~Petal.Length|Species, col=unclass(Species), panel=panel.smooth)

> coplot(Sepal.Length~Petal.Length | cut(Sepal.Width,4) * cut(Petal.Width,2), col=unclass(Species), panel=panel.smooth)

R - Recoding (missing) values in a matrix
let v be a vector
> v <- c(1,2,4,99,6,999,7,8,99,5,2,4,9,2)
where the missing values where coded as 9, 99 or 999.
Then the fastest way (i know) to recode them is:
> v[v %in% c(9,99,999)] <- NA
> v
[1] 1 2 4 NA 6 NA 7 8 NA 5 2 4 NA 2
an example with matrices:
> m <- matrix(1:12, nrow=3, byrow=T,dimnames = list(letters[1:3],LETTERS[1:4])) > m
A B C D
a 1 2 3 4
b 5 6 7 8
c 9 10 11 12
> m[m %in% c(9,99,999)] <- NA
> m
A B C D
a 1 2 3 4
b 5 6 7 8
c NA 10 11 12
This does not work on dataframes. You have to operate on each column separately. If you have many columns maybe it is worth a try to load the package epicalc or lordif and use the command recode() or you do it in loop ...
> v <- c(1,2,4,99,6,999,7,8,99,5,2,4,9,2)
where the missing values where coded as 9, 99 or 999.
Then the fastest way (i know) to recode them is:
> v[v %in% c(9,99,999)] <- NA
> v
[1] 1 2 4 NA 6 NA 7 8 NA 5 2 4 NA 2
an example with matrices:
> m <- matrix(1:12, nrow=3, byrow=T,dimnames = list(letters[1:3],LETTERS[1:4])) > m
A B C D
a 1 2 3 4
b 5 6 7 8
c 9 10 11 12
> m[m %in% c(9,99,999)] <- NA
> m
A B C D
a 1 2 3 4
b 5 6 7 8
c NA 10 11 12
This does not work on dataframes. You have to operate on each column separately. If you have many columns maybe it is worth a try to load the package epicalc or lordif and use the command recode() or you do it in loop ...
Column View for Properties (Org-Mode)
The part of my org-file which I want to make look like a table:
* Spreadsheetsall of the spreadsheets have the following properties:
** all children, one measurement
** Interval 2 years / one measurement per child
** Interval 4 years / one measurement per child
** Interval 6 years / one measurement per child
:PROPERTIES:If I want to use column view on them, I have to define the columns. Because I want all of my spreadsheets in my view first I
:sqlfile: [[file:2jahre.sql]]
:perlfile: [[file:2jahresds.pl]]
:sqloutput: link to file
:result: [[file:20110421/2jahresds.txt]]
:END:
- define a property :COLUMNS: for my Spreadsheets; the value of this property should have the following form: %sqlfile %perlfile %result; a number right after the percent sign specify the width of the column; and you can add a title in square brackets; (%20sqlfile[SQL] defines the column containing the property sqlfile, this column has width 20 and the header SQL)
* Spreadsheets
:PROPERTIES:
:COLUMNS: %20sqlfile %20perlfile %20sqloutput %result
:END:
** all children, one measurement... - typing C-c C-x C-c with the courser in the section Spreadsheets starts column view; q - exit column view; r - refresh column view, use the arrow keys for navigation through the table, type e for editing a field
Datetime in Org-Mode
- insert a date: C-c . (active) C-c ! (inactive)
- insert a datetime: C-u C-c . (active) C-u C-c ! (inactive)
Saturday, June 4, 2011
Tables in Org-Mode
- draw horizontal line: type |- and hit TAB
- draw a horizontal line beneath the actual line: C-c RET
- create a table from a region: C-c |
- Move to the beginning of the field: M-a
- Move to the end of the field: M-e
- Move the current column left/rigth: M-left/M-right
- Kill the current column: M-S-left
- Insert a new column to the left of the cursor: M-S-right
- Move current row up/down: M-up/down
- Kill current row or horizontal line: M-S-up
- Insert a new row above the current line: M-S-down
- Sort table lines in region: C-c ^
- Sum the numbers of a column or rectangle region: C-c + ; insert with C-y
- Copy rectangular region: C-c C-x M-w
- Cut rectangular region: C-c C-x C-w
- Wrap several fields in a column like a paragraph: M-RET
- Copy from or to the next non empty or empty field: S-RET
- Edit current field in separate window: C-c '
- Import file as a table: M-x org-table-import
- Export table (as tab-sep file): M-x org-table-export
clean up the outline view in org-mode (less stars)
In Emacs Org-Mode outlines look like these:
* heading 3
** subheading 3.1
*** one more heading 3.1.1
*** one more heading 3.1.2
to clean up the outline view, start org-ident-mode
> M-x org-indent-mode RET change view to
* heading 3
* subheading 3.1
* one more heading 3.1.1
* one more heading 3.1.2
* heading 3
** subheading 3.1
*** one more heading 3.1.1
*** one more heading 3.1.2
to clean up the outline view, start org-ident-mode
> M-x org-indent-mode RET change view to
* heading 3
* subheading 3.1
* one more heading 3.1.1
* one more heading 3.1.2
Friday, June 3, 2011
Adding a public key
gpg --keyserver keyserver.ubuntu.com --recv keyid
gpg --export --armor keyid | sudo apt-key add -
gpg --export --armor keyid | sudo apt-key add -
read data into R via the clipboard
I tested this on Windows (Excel) and Ubuntu (Gnumeric) and it is a nice little feature which can save a lot of time. If you copy a data table in a spreadsheet into the clipboard you can read the data into R with
> x <- read.delim("clipboard", na.str=".", header=T)
Do not try it with really big tables... ;)
on mac there is something similar, I made a note when we tried it on a mac during a course but i do not remember exactly and can not test it because i do not own a macbook...
> read.table(pipe("pbpaste"))
> x <- read.delim("clipboard", na.str=".", header=T)
Do not try it with really big tables... ;)
on mac there is something similar, I made a note when we tried it on a mac during a course but i do not remember exactly and can not test it because i do not own a macbook...
> read.table(pipe("pbpaste"))
Creating Factors
reorder is fantastic to change the order of factors. If you import some data which contains a factor the factor levels are ordered according to the alphabet. This is also the sequence shown in graphics. So the levels "good", "better", "best" are displayed in reverse order.
Here are some examples showing how to create an ordered factor (in the order you want) out of an other:
if you have a numeric vector - and you want to label it
> taste <- rep(0:2,c(5,5,5)) # create the numeric vector > taste
[1] 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2
# make a factor out auf it
> taste <- factor(taste, levels=0:2, labels=c("good","better","best"))
> taste
[1] good good good good good better better better better better
[11] best best best best best
Levels: good better best
> taste <- rep(0:2,5) # different use of rep
> taste
[1] 0 1 2 0 1 2 0 1 2 0 1 2 0 1 2
> taste <- factor(taste, levels=0:2, labels=c("good","better","best"))
> taste
[1] good better best good better best good better best good
[11] better best good better best
Levels: good better best
> taste <- letters[rep(1:3,5)] # create a vector containing characters/strings
> taste
[1] "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c"
> taste <- factor(taste, levels=c("c","b","a"), labels=c("good","better","best"))
> taste
[1] best better good best better good best better good best
[11] better good best better good
Levels: good better best
there is also gl
> my.factor <- gl(number.of.levels,number.of.replications,labels=c(.....)) e.g.
> my.factor <- gl(3,4,labels=c("yes","maybe","no"))
> my.factor
[1] yes yes yes yes maybe maybe maybe maybe no no no no
Levels: yes maybe no
Here are some examples showing how to create an ordered factor (in the order you want) out of an other:
if you have a numeric vector - and you want to label it
> taste <- rep(0:2,c(5,5,5)) # create the numeric vector > taste
[1] 0 0 0 0 0 1 1 1 1 1 2 2 2 2 2
# make a factor out auf it
> taste <- factor(taste, levels=0:2, labels=c("good","better","best"))
> taste
[1] good good good good good better better better better better
[11] best best best best best
Levels: good better best
> taste <- rep(0:2,5) # different use of rep
> taste
[1] 0 1 2 0 1 2 0 1 2 0 1 2 0 1 2
> taste <- factor(taste, levels=0:2, labels=c("good","better","best"))
> taste
[1] good better best good better best good better best good
[11] better best good better best
Levels: good better best
> taste <- letters[rep(1:3,5)] # create a vector containing characters/strings
> taste
[1] "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c" "a" "b" "c"
> taste <- factor(taste, levels=c("c","b","a"), labels=c("good","better","best"))
> taste
[1] best better good best better good best better good best
[11] better good best better good
Levels: good better best
there is also gl
> my.factor <- gl(number.of.levels,number.of.replications,labels=c(.....)) e.g.
> my.factor <- gl(3,4,labels=c("yes","maybe","no"))
> my.factor
[1] yes yes yes yes maybe maybe maybe maybe no no no no
Levels: yes maybe no
IDEs for R
First of all I strongly recommend emacs (because this is the one I use everyday - and I LOVE it, but I use Emacs for everything. It is definitely worth a try, especially if you like to work with shortcuts, but you need a lot of patience in the beginning.)
Ubuntu:
After installing R and emacs install the package "ess" via apt-get or Synaptic;
start emacs, type "M-x R", hit the Enter key - and here we are: Welcome to "emacs speaks statistic"
Win and Mac:
the configuration is - and that is what I read on the web - much more difficult, so the best you can do, is downloading the all-in-one-package provided by Vincent Goulet (i.e. it contains emacs and ess and some other add ons and is already configurated). Of course you can try to do it on yourself and maybe report on your experiences, I am very interested. However here is the link
I used it on Ubuntu, WinXP and Win7. Works fine on every OS (Emacs and Linux works best)
The Rcommander is a integrated GUI; start R, install the package "Rcmdr": install.packages("Rcmdr", dependencies=T), start the Rcommander with library(Rcmdr)
Here is a link for further informations.. It works on all platforms.
I saw it a few times, i worked with it three or five times. But it is all I can say about it.
Rstudio is a nice IDE, also available for Win, Mac, Linux. If you do not want to use emacs try this or Tinn-R (only Win); the recommended download link for Tinn-R is http://sourceforge.net/projects/tinn-r/
Deducer - it looks very nice: data editor, menues, etc pp the homepage is: www.deducer.org.
For windows there is a msi which installs all you need, if R is already installed there are some packages you need additional - and you need a current Java version.
Everybody who likes to or used to work with SPSS or something like this - try it. The graph builder (works with ggplot2) is really nice.
some I heard of:
http://rforge.net/JGR/
http://rattle.togaware.com/ (data mining - will try it soon...)
To be continued...
Ubuntu:
After installing R and emacs install the package "ess" via apt-get or Synaptic;
start emacs, type "M-x R", hit the Enter key - and here we are: Welcome to "emacs speaks statistic"
Win and Mac:
the configuration is - and that is what I read on the web - much more difficult, so the best you can do, is downloading the all-in-one-package provided by Vincent Goulet (i.e. it contains emacs and ess and some other add ons and is already configurated). Of course you can try to do it on yourself and maybe report on your experiences, I am very interested. However here is the link
I used it on Ubuntu, WinXP and Win7. Works fine on every OS (Emacs and Linux works best)
The Rcommander is a integrated GUI; start R, install the package "Rcmdr": install.packages("Rcmdr", dependencies=T), start the Rcommander with library(Rcmdr)
Here is a link for further informations.. It works on all platforms.
I saw it a few times, i worked with it three or five times. But it is all I can say about it.
Rstudio is a nice IDE, also available for Win, Mac, Linux. If you do not want to use emacs try this or Tinn-R (only Win); the recommended download link for Tinn-R is http://sourceforge.net/projects/tinn-r/
Deducer - it looks very nice: data editor, menues, etc pp the homepage is: www.deducer.org.
For windows there is a msi which installs all you need, if R is already installed there are some packages you need additional - and you need a current Java version.
Everybody who likes to or used to work with SPSS or something like this - try it. The graph builder (works with ggplot2) is really nice.
some I heard of:
http://rforge.net/JGR/
http://rattle.togaware.com/ (data mining - will try it soon...)
To be continued...
R - convert date into day of year
strptime contains a lot of functionality to converting a date (type ?strptime for details).
For converting a Y-m-d given date into a day-of-year number use the following syntax:
strptime(c("2011-03-04","2010-01-01"), "%Y-%m-%d")$yday+1
(you have to add 1 because the counting starts at 0)
if your date is given in a different format change the second argument within the brackets
e.g. for "01.10.1999":
strptime("01.10.1999, "%d.%m.%Y")$yday+1
more on dates with the lubridate package
more on dates with the format command
For converting a Y-m-d given date into a day-of-year number use the following syntax:
strptime(c("2011-03-04","2010-01-01"), "%Y-%m-%d")$yday+1
(you have to add 1 because the counting starts at 0)
if your date is given in a different format change the second argument within the brackets
e.g. for "01.10.1999":
strptime("01.10.1999, "%d.%m.%Y")$yday+1
more on dates with the lubridate package
more on dates with the format command
Subscribe to:
Comments
(
Atom
)